

Home > CC2 > Chapter 9 > Lesson 9.1.2 > Problem 9-38
9-38.
Stuart is a plumber working on the Garcia family’s house. He is working with PVC pipe that has an internal diameter of
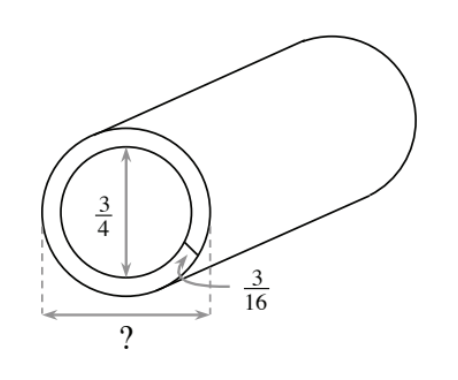
The diameter of the exterior of the pipe is equal to the interior diameter plus two times the thickness of the pipe, because from one side of the pipe to the other, the thickness of the pipe is included two times.
Find a common denominator and add.