

Home > CC3 > Chapter 9 > Lesson 9.1.2 > Problem 9-21
9-21.
Find the measure of the missing angle in each triangle below and then classify the triangle as acute, right, or obtuse.
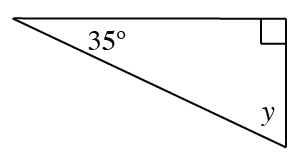
Angle
and the angle are complementary.
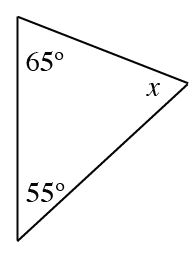
The sum of the interior angles in a triangle is always
.