

Home > PC > Chapter 2 > Lesson 2.3.4 > Problem 2-111
2-111.
The sum of the areas for the right-endpoint rectangles of the function
What does
represent? Width
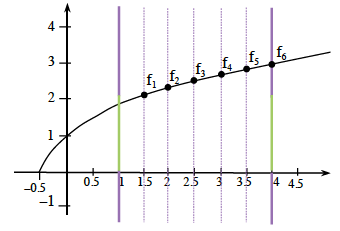
Let
. Use what you know to find the sum of the areas of the right-endpoint rectangles of on . The
in the express raises the function up . So the total area is increased by because the base was . Find the sum of the
right-endpoint rectangles for for . Since the whole graph is raised up
and the base is still , how much more area would the new function have than ?